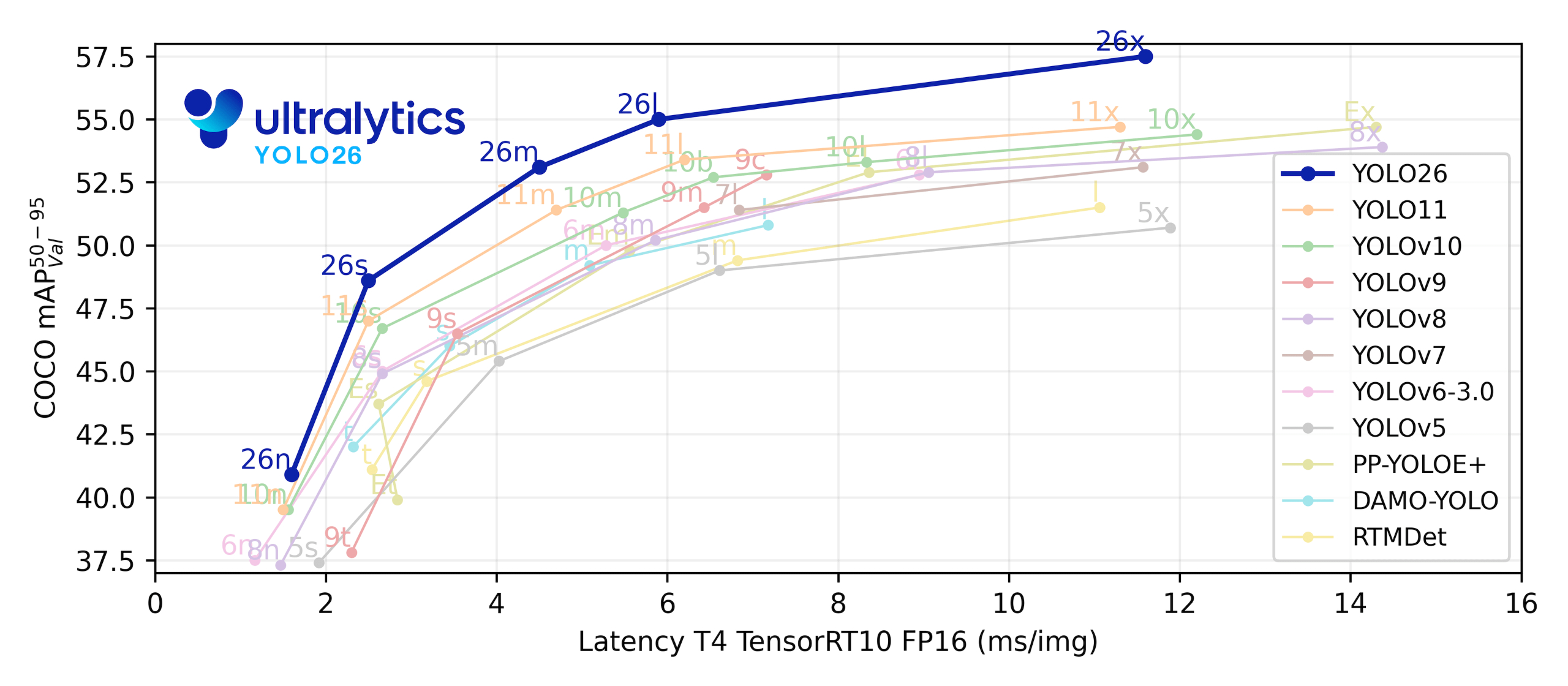
北京时间 2026 年 1 月 14 日,YOLO26 终于正式揭开了面纱。
这一次,我们不谈它在学术圈引发了多少讨论,也不去纠结那些在论文榜单上微乎其微的 mAP 涨幅。对于我们这些在一线“拧螺丝”的开发者来说,YOLO26 的意义在于它完成了一次彻底的工程化突围。
它的设计目标不再是单纯的“刷分”,而是直指落地的三大痛点:端到端、轻量化、易部署。官方文档明确抛弃了繁琐的 NMS 后处理,去掉了拖累部署的 DFL,换来的是在 CPU 上最高 43% 的性能暴涨。
系统拆解 YOLO26 如何通过“做减法”,为工程落地带来真金白银的效率红利。
一、 改进目标:更简单、更快、更易部署
YOLO26 的总体目标非常务实,可以总结为三点:
推理链路简化:用端到端检测替代传统的 NMS 作为后处理阶段,彻底消除额外的推理开销与复杂的部署适配逻辑。
部署效率提升:坚决去掉 DFL 模块,避免导出时的复杂度和硬件适配瓶颈,减少边缘设备上的推理依赖。
训练优化与任务增强:引入 MuSGD 和分割、姿态、OBB的多任务专用优化,将大模型训练与任务特化技术移植到视觉端。
从目标层面看,YOLO26 并不是一个“更复杂的模型”,而是一个更可落地的工程化版本:减轻后处理、缩短部署链路、强化训练收敛与多任务能力,这些改进刀刀见血,直接面向生产场景痛点。
二、 架构与推理流程的核心变化
1. 端到端 NMS-free 推理:从架构层面消除后处理
YOLO26 使用端到端结构输出最终预测,不再依赖 NMS。
在配置中,我们只需要设置 end2end: True 即可打开端到端模式;同时,检测头会为 one-to-one 分支保留独立路径,从而在推理时直接输出结果。【ultralytics/cfg/models/26/yolo26.yaml†L7-L9】【ultralytics/nn/modules/head.py†L80-L178】
推理后处理的代码逻辑也体现了这一剧变:NMS 函数现在加入了一个判断——在输入预测为 end-to-end 时,会直接返回结果,不再执行复杂的 NMS 过滤逻辑。【ultralytics/utils/nms.py†L12-L85】
工程影响:
推理路径更短,部署管线不再需要额外编写后处理代码;
对边缘环境更友好,减少了因后处理计算带来的不确定性和延迟抖动。
2. DFL Removal:回归更轻的输出分布
YOLO26 在配置中把 reg_max 设置为 1,从而取消了 DFL 多 bin 的离散回归输出。这意味着 head 中的 DFL 层会退化为简单的恒等映射。【ultralytics/cfg/models/26/yolo26.yaml†L7-L9】【ultralytics/nn/modules/head.py†L80-L110】
这一改动去掉了 DFL,极大简化了模型结构、降低导出复杂度,并增强了边缘硬件的兼容性。
工程影响:
导出流程更稳定、图结构更简单;
对资源敏感设备显著减少了计算与内存开销。
三、 训练与优化策略的关键升级
1. MuSGD:从 LLM 训练迁移来的优化器融合
YOLO26 引入了 MuSGD 作为新的训练优化器,这是来自 Muon 与 SGD 的混合实现。优化器定义在 ultralytics/optim/muon.py,并在训练器中作为自动选择分支的一部分出现,可以与 SGD 并列使用。【ultralytics/optim/muon.py†L99-L176】【ultralytics/engine/trainer.py†L947-L996】
通过引入大语言模型训练的优化经验,MuSGD 实现了更稳定、更快的收敛表现。
工程影响:
训练阶段更稳,特别适合边缘模型训练时对效率与收敛的双重要求;
有望降低调参成本,改善训练效率与最终精度。
2. ProgLoss + STAL:小目标检测的专用增益
YOLO26 使用 ProgLoss + STAL 来提升小目标识别能力,这是 Edge AI 场景(如无人机、IoT)中最关键的精度痛点之一。
工程影响:
小物体、密集场景精度表现更稳定;
特化损失函数带来的增益在生产场景中更容易被感知。
下面是环境安装、编译、运行教程
CUDA Toolkit 13.1.0 (December 2025), Versioned Online Documentation
CUDA Toolkit 13.0.2 (October 2025), Versioned Online Documentation
CUDA Toolkit 13.0.1 (September 2025), Versioned Online Documentation
CUDA Toolkit 13.0.0 (August 2025), Versioned Online Documentation
CUDA Toolkit 12.9.1 (June 2025), Versioned Online Documentation
CUDA Toolkit 12.9.0 (May 2025), Versioned Online Documentation
CUDA Toolkit 12.8.1 (March 2025), Versioned Online Documentation
CUDA Toolkit 12.8.0 (January 2025), Versioned Online Documentation
设置conda的添加清华源对于 main 和 free 通道,创建虚拟环境更快
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ #设置搜索时显示通道地址 conda config --set show_channel_urls yes #临时使用清华源 conda install <package_name> -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main #如果需要恢复默认源 conda config --remove-key channels #设置后首次使用可能需要清除缓存 conda clean -i
官方最简洁安装,一行命令安装CPU版本
https://docs.ultralytics.com/zh/#what-is-ultralytics-yolo-and-how-does-it-improve-object-detection
pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
需要设置独显,可以参考以下操作
##设置代理 conda config --set proxy_servers.http http://127.0.0.1:10808 conda config --set proxy_servers.https http://127.0.0.1:10808 ##取消代理 conda config --remove-key proxy_servers.http conda config --remove-key proxy_servers.https conda create -n yolo26 python=3.10 conda activate yolo26 ##下载安装对应的cuda开发包 https://developer.nvidia.com/cuda-toolkit-archive nvidia-smi +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 581.57 Driver Version: 581.57 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce GTX 1050 ... WDDM | 00000000:01:00.0 On | N/A | | N/A 47C P8 N/A / 5001W | 940MiB / 4096MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ https://pytorch.org/ 查询对应安装的版本 #安装环境 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130 #查看版本 python -c "import torch; print(torch.__version__)" PyTorch Version: 2.10.0+cu130 CUDA Available: True GPU Device: NVIDIA GeForce GTX 1050 Ti with Max-Q Design #cpu版本 pip3 install torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple #输出结果:torch.__version__输出值2.10.0+cpu #安装结果 Installing collected packages: mpmath, typing-extensions, sympy, pillow, numpy, networkx, MarkupSafe, fsspec, filelock, jinja2, torch, torchvision Successfully installed MarkupSafe-2.1.5 filelock-3.20.0 fsspec-2025.12.0 jinja2-3.1.6 mpmath-1.3.0 networkx-3.6.1 numpy-2.3.5 pillow-12.0.0 sympy-1.14.0 torch-2.10.0+cu130 torchvision-0.25.0+cu130 typing-extensions-4.15.0 #测试 python import torch print(torch.cuda.is_available()) True exit() #安装库,源码根目录 --no-dep 参数,但通常不建议这样做,除非你确定环境已经完全配好,不添加,会被修改为cpu版本 pip install ultralytics . ###如果想切换版本,使用以下命令行清理安装 pip uninstall torch torchvision torchaudio -y
-

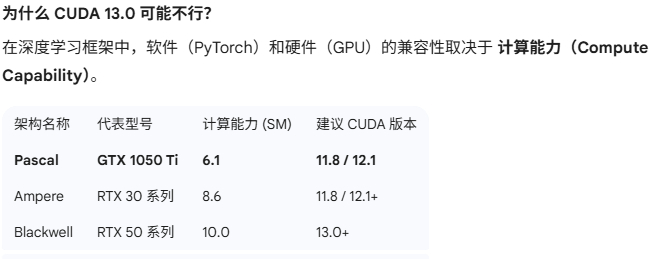
笔记本显卡1050ti太老,cuda130产支持
NVIDIA GeForce GTX 1050 Ti with Max-Q Design with CUDA capability sm_61 is not compatible with the current PyTorch installation.
解决方案:安装兼容 Pascal 架构的稳定版
对于 1050 Ti 这种 Pascal 架构的显卡,使用 CUDA 11.8 或 12.1 是最安全的选择,因为这些版本被广泛编译并包含
sm_61的支持。第一步:卸载当前的错误版本
先清理掉不兼容的 PyTorch 及其相关组件:
pip uninstall torch torchvision torchaudio
第二步:安装兼容版本(推荐 CUDA 12.1)
目前 Ultralytics (YOLO26) 在 CUDA 12.1 下运行非常稳定,且 1050 Ti 的驱动完全可以向下兼容。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 #代理 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 --proxy http://127.0.0.1:10808
import torch print(f"PyTorch 版本: {torch.__version__}") print(f"CUDA 是否可用: {torch.cuda.is_available()}") if torch.cuda.is_available(): print(f"当前设备: {torch.cuda.get_device_name(0)}") print(f"设备算力: {torch.cuda.get_device_capability(0)}") # 尝试创建一个简单的张量并移动到 GPU try: x = torch.ones(1).cuda() print("测试成功:张量已成功移动到 GPU!") except Exception as e: print(f"测试失败: {e}") -
AMD,解决方案,未测试
Linux 原生 / WSL2 命令:
# 先卸载旧版本 pip uninstall torch torchvision torchaudio -y # 安装 ROCm 适配版 PyTorch pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2
Windows 直接运行 (DirectML 方案):
如果你不想折腾 WSL2,可以使用专门的 DirectML 插件:
pip install torch-directml
注意:DirectML 方案在 YOLO 上的兼容性略逊于 ROCm,且代码需稍作修改。
3. 修改 YOLO 训练脚本
YOLO 默认会尝试调用 cuda。在使用 AMD ROCm 时,代码通常可以透明切换,因为 ROCm 模拟了 CUDA 接口。
标准 ROCm (Linux/WSL2) 运行方式:
只要 torch.cuda.is_available() 返回 True(ROCm 成功模拟了该接口),你直接像平时一样训练即可:
from ultralytics import YOLO model = YOLO("yolov11n.pt") # YOLO 会自动识别 ROCm 环境为 'cuda' results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=0)验证环境:
运行以下 Python 代码,如果输出包含 AMD 字样,说明成功:
import torch print(torch.cuda.is_available()) print(torch.cuda.get_device_name(0)) # 应该显示类似 'AMD Radeon...'
性能优化建议
使用 Docker(推荐):AMD 官方提供了预装好 ROCm 环境的 Docker 镜像,这是最省心的方式:
docker pull rocm/pytorch:latest半精度训练 (FP16):AMD 显卡对 FP16 支持良好,确保在
model.train()中保持half=True(默认通常开启)。
- 文章2323
- 用户1338
- 访客12458839
未读完的书页间,栖居着寂静的走廊。