想了解Java服务器的深层高阶知识,Netty绝对是一个必须要过的门槛。
有了Netty,你可以实现自己的HTTP服务器,FTP服务器,UDP服务器,RPC服务器,WebSocket服务器,Redis的Proxy服务器,MySQL的Proxy服务器等等。如果你想知道Nginx是怎么写出来的,如果你想知道Tomcat和Jetty是如何实现的,如果你也想实现一个简单的Redis服务器,那都应该好好理解一下Netty,它们高性能的原理都是类似的。今天就学习下Netty的粘包,这是TCP协议必须要掌握的。
客户端在一个for循环内连续发送1000个hello给Netty服务器端
Socket socket = new Socket("127.0.0.1", 10101);
for(int i = 0; i < 1000; i++){
socket.getOutputStream().write(“hello”.getBytes());
}
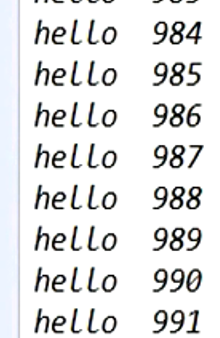
socket.close();而在服务器端接受到的信息并不是预期的1000个独立的Hello字符串.
实际上是无序的hello字符串混合在一起, 如图所示. 这种现象我们称之为粘包.

为什么会出现这种现象呢? TCP是个”流”协议,流其实就是没有界限的一串数据。
TCP底层中并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包划分,
所以在TCP中就有可能一个完整地包会被TCP拆分成多个包,也有可能吧多个小的包封装成一个大的数据包发送。
分包处理
顾名思义, 我们要对传输的数据进行分包. 一个简单的处理逻辑是在发送数据包之前, 先用四个字节占位, 表示数据包的长度.
数据包结构为:
| 长度(4字节) | 数据 |
Socket socket = new Socket("127.0.0.1", 10101);
String message = "hello";
byte[] bytes = message.getBytes();
ByteBuffer buffer = ByteBuffer.allocate(4 + bytes.length);
// 消息长度
buffer.putInt(bytes.length);
// 消息正文
buffer.put(bytes);
byte[] array = buffer.array();
for(int i = 0; i < 1000; i++){
socket.getOutputStream().write(array);
}
socket.close();服务器端代码, 我们需要借助于FrameDecoder类来分包.
public class MyDecoder extends FrameDecoder {
@Override
protected Object decode(ChannelHandlerContext ctx, Channel channel, ChannelBuffer buffer) throws Exception {
if(buffer.readableBytes() > 4){
//标记
buffer.markReaderIndex();
//长度
int length = buffer.readInt();
if(buffer.readableBytes() < length){
buffer.resetReaderIndex();
//缓存当前剩余的buffer数据,等待剩下数据包到来
return null;
}
//读数据
byte[] bytes = new byte[length];
buffer.readBytes(bytes);
//往下传递对象
return new String(bytes);
}
//缓存当前剩余的buffer数据,等待剩下数据包到来
return null;
}
}如此一来, 我们再次在服务器端接受到的消息就是按序打印的hello了.
这边可能有个疑问, 为什么MyDecoder中数据没有读取完毕, 需要return null,
正常的pipeline在数据处理完都是要sendUpstream, 给下一个pipeline的.
这个需要看下FrameDecoder.messageReceived 的源码. 他在其中缓存了一个cumulation对象,
如果return了null, 他会继续往缓存里写数据来实现分包
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) throws Exception {
Object m = e.getMessage();
if (!(m instanceof ChannelBuffer)) {
// 数据读完了, 转下一个pipeline
ctx.sendUpstream(e);
} else {
ChannelBuffer input = (ChannelBuffer)m;
if (input.readable()) {
if (this.cumulation == null) {
try {
this.callDecode(ctx, e.getChannel(), input, e.getRemoteAddress());
} finally {
this.updateCumulation(ctx, input);
}
} else {
// 缓存上一次没读完整的数据
input = this.appendToCumulation(input);
try {
this.callDecode(ctx, e.getChannel(), input, e.getRemoteAddress());
} finally {
this.updateCumulation(ctx, input);
}
}
}
}
}那么是不是这样就万事大吉了呢?
Socket字节流攻击
在上述代码中, 我们会在服务器端为客户端发送的数据包长度, 预先分配byte数组.
如果遇到恶意攻击, 传入的数据长度与内容 不匹配. 例如声明数据长度为Integer.MAX_VALUE.
这样会消耗大量的服务器资源生成byte[], 显然是不合理的.
因此我们还要加个最大长度限制.
if(buffer.readableBytes() > 2048){
buffer.skipBytes(buffer.readableBytes());
}新的麻烦也随之而来, 虽然可以跳过指定长度, 但是数据包本身就乱掉了.
因为长度和内容不匹配, 跳过一个长度后, 不知道下一段数据的开头在哪里了.
因此我们自定义数据包里面, 不仅要引入数据包长度, 还要引入一个包头来划分各个包的范围.
包头用任意一段特殊字符标记即可, 例如$$$.
// 防止socket字节流攻击
if(buffer.readableBytes() > 2048){
buffer.skipBytes(buffer.readableBytes());
}
// 记录包头开始的index
int beginReader = buffer.readerIndex();
while(true) {
if(buffer.readInt() == ConstantValue.FLAG) {
break;
}
}新的数据包结构为:
| 包头(4字节) | 长度(4字节) | 数据 |
Netty自带拆包类
自己实现拆包虽然可以细粒度控制, 但是也会有些不方便, 可以直接调用Netty提供的一些内置拆包类.
- FixedLengthFrameDecoder 按照特定长度组包
- DelimiterBasedFrameDecoder 按照指定分隔符组包, 例如本文中的$$$
- LineBasedFrameDecoder 按照换行符进行组包, \r \n等等
- ......
本文链接:https://it72.com:4443/12355.htm